
July 6, 2017 •Shane Thompson

Summit's Dr. Shane Thompson writes about the importance of administrative data in impact evaluations in his three-part blog series. In his second blog, below, he writes about administrative data methodologies. Those interested in reading more about program evaluation can download Summit's latest white paper here.
Much more often than not, your administrative dataset is not immediately ready for an impact evaluation. The dataset holds a wealth of information, but without a proper methodological approach you may only be able to extract summary statistics of the program, leaving the true impact of the program left unmeasured. (See the previous post in this series for the pitfalls of substituting summary statistics for impact evaluations).
Any impact evaluation involves a treatment group and control group. Administrative datasets, unlike randomized controlled trials, do not have well-defined treatment and control groups. Accordingly, the challenge facing an impact evaluator with administrative data is establishing the control group.
Statisticians and econometricians have developed an array of methodological tools to establish quasi-control groups when they do not actually exist. We describe some of these methods, how they work, and when to use each one in the table below.
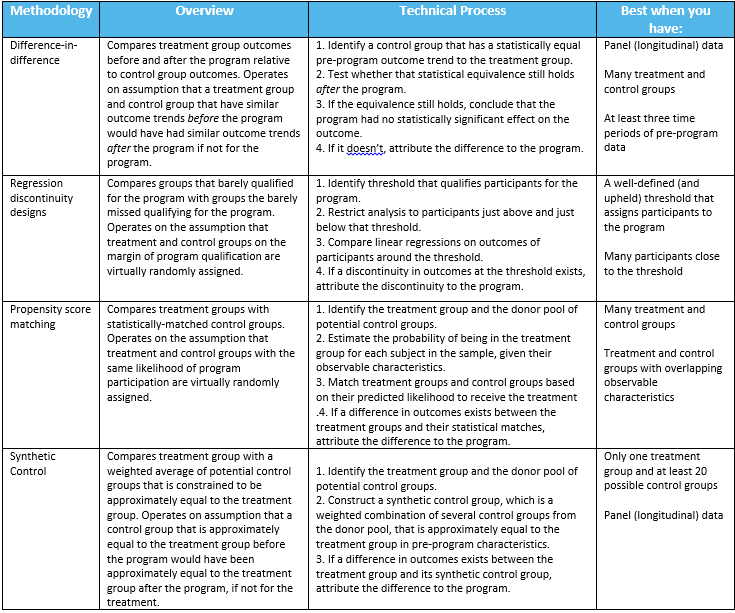
Difference-in-difference methods, regression discontinuity designs, and propensity score matching are well-established techniques. The synthetic control method is relatively new and provides an innovative approach to impact evaluation. In the last post of this blog series, I implement the synthetic control method on actual data.
Interested in reading more about this topic? Dr. Thompson co-authored a white paper on estimation designs used in program evaluation, which can be downloaded below.
